Welcome to our Blog on “Top 20 Kafka Interview Questions and Answers for 2023.” If you are preparing for Kafka Interview then, this post will help you and assist you to crack Apache Kafka Interview. Here we are covering most relevant and frequently asked Kafka interview questions and ensuring that you are well-prepared to clear the interview. We have tried to provide best answers to each question, offering valuable insights and boosting your confidence. So, let’s jump into these top 20 Kafka interview questions and set you on the path to success in all your Kafka-related endeavors!
You can also visit our official YouTube Channel EasyWay2Learn to see our RPA Training Videos.

List of commonly asked Kafka Interview Questions and Answers
What is Kafka and what are its main components?
Apache Kafka is a distributed streaming platform that is used for building real-time data pipelines and streaming applications. It was originally developed by LinkedIn and was later open-sourced and donated to the Apache Software Foundation.
Kafka is designed to handle huge volumes of real-time data. By providing a scalable, fault-tolerant, and low-latency platform for publishing and processing data streams.
The main components of Apache Kafka are as follows:
-
Broker: A Kafka broker is a server that stores and manages data streams. It is responsible for receiving, storing and replicating data across multiple nodes.
-
Topic: A Kafka topic is a category or feed name to which records are published. Topics can be partitioned to allow for parallel processing and increased scalability.
-
Producer: A Kafka producer is a client application that publishes messages to a topic. Producers can publish messages in batches or individually.
-
Consumer: A Kafka consumer is a client application that subscribes to a topic and reads messages from it. Consumers can read messages in batches or individually.
-
Partition: A partition is a unit of parallelism in Kafka that allows data streams to be split across multiple brokers. Partitions are used to distribute the load and improve performance.
-
Offset: An offset is a unique identifier assigned to each message in a partition. It is used by consumers to keep track of their progress and to ensure that each message is processed only once.
-
ZooKeeper: It is a distributed coordination service. It is used by Kafka to manage its configuration, maintain cluster membership and perform leader election.

How does Kafka handle fault-tolerance and ensure data durability?
Kafka is a distributed streaming platform that is designed to handle large volumes of real-time data with high fault-tolerance and data durability. Kafka achieves this by utilizing several techniques, including replication, partitioning, and write-ahead logging.
To ensure fault-tolerance, Kafka uses replication to create multiple copies of data across different brokers. This means that if one broker fails, data can still be accessed from other brokers that have a replica of the data. Additionally, Kafka’s partitioning system allows data to be split across multiple brokers, enabling parallel processing and improved scalability.
To ensure data durability, it uses a write-ahead logging approach. When a producer publishes a message to a topic, the message is first written to a log file on the disk of the Kafka broker. This ensures that the message is durably stored and can be recovered in case of a broker failure.
Also, Kafka allows consumers to control their position in the log by maintaining their own offset. This means that if a consumer fails. It can resume from its last known offset and continue consuming messages from where it left off.
Finally, Kafka utilizes ZooKeeper to coordinate and manage the cluster. ZooKeeper maintains the configuration and state of the Kafka brokers and ensures. That the cluster remains stable and functional even in the event of failures.
What is the difference between a Kafka topic and a Kafka partition?
In Kafka, a topic is a category or feed name to which messages are published by the producers. While a partition is a smaller, ordered, and immutable sequence of messages within a topic. Topics are the top-level concept in Kafka that represent a logical stream of data. Whereas partitions are the physical units that store and distribute messages across the Kafka cluster. Here is the list of differences between Kafka Topic and Partition.
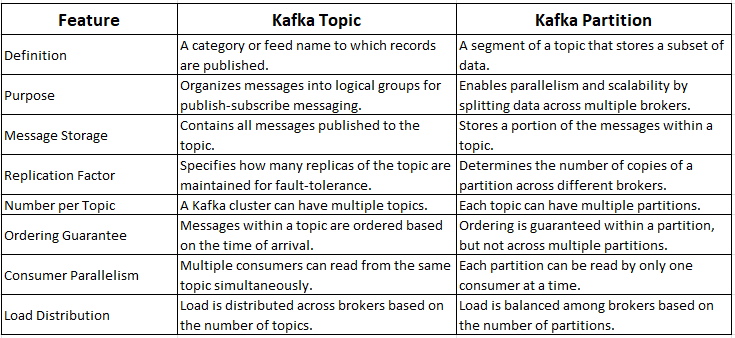
How does Kafka ensure data consistency across its distributed cluster?
Kafka is a distributed streaming platform that enables real-time data processing by distributing data across multiple brokers. To ensure data consistency across the cluster, Kafka uses a combination of techniques, including replication, partitioning and leader election.
Replication is one of the key mechanisms used by Kafka to ensure data consistency. When a message is published to a topic, Kafka replicates it to multiple brokers across the cluster. These replicas are kept in sync with the leader partition. Which is responsible for handling all read and write requests for a particular partition. If the leader partition fails, one of the replicas is automatically elected as the new leader, ensuring that data consistency is maintained.
Partitioning is another technique used by Kafka to ensure data consistency. Each topic in Kafka is divided into one or more partitions, and each partition is hosted on a different broker in the Kafka cluster. This allows for parallel processing of messages and improves scalability. The partitioning scheme is configurable and can be based on a hashing function or a round-robin approach.
Finally, Kafka uses a leader election process to ensure data consistency in case of broker failures. If a leader partition fails, one of the replicas is automatically elected as the new leader. This ensures that the new leader has an up-to-date copy of the data and can continue serving read and write requests without any data loss.
What is a Kafka producer, and how does it differ from a Kafka consumer?
A Kafka producer is a component that generates and publishes data or messages to a Kafka topic. It’s responsible for sending data to the Kafka cluster, where it’s then made available to Kafka consumers for processing. Producers can be developed in various programming languages like Java, Python, Scala, and more.
Producers send messages to one or more Kafka topics in a continuous stream. These messages can be anything from log entries, user data, application events, or any other form of data. The producer API allows developers to configure message delivery guarantees. Such as at-least-once, exactly-once, or at-most-once semantics to ensure message delivery reliability.
On the other hand, a Kafka consumer is a component that subscribes to one or more Kafka topics and receives messages published by producers. Consumers can be implemented in various programming languages like Java, Python, Scala, and more. Kafka consumers consume messages in the order they were produced.
Consumers can consume messages either in batches or one at a time. In batch mode, the consumer fetches a batch of messages from the Kafka broker before processing them. In one-at-a-time mode, the consumer fetches messages one at a time and processes them in sequence.
The main difference between Kafka producers and consumers is their role in the Kafka ecosystem. While producers generate and publish data or messages to Kafka topics, consumers subscribe to Kafka topics and process messages. Producers send messages to one or more Kafka topics, while consumers read messages from one or more Kafka topics.
What is a Kafka broker, and what is its role in a Kafka cluster?
A Kafka broker is a component in a Kafka cluster that is responsible for managing and storing Kafka topic partitions. In simple terms, a Kafka broker acts as a middleman between Kafka producers and consumers, handling the storage and delivery of messages.
Each Kafka broker in a cluster is identified by a unique integer identifier and can be thought of as a standalone Kafka server. The brokers work together to provide fault-tolerant and scalable storage for Kafka messages.
The role of a Kafka broker in a Kafka cluster is critical. It receives messages from Kafka producers, stores them in a durable way, and makes them available to Kafka consumers. The broker also maintains metadata about the Kafka cluster. Including the topics and partitions it contains and which broker is the leader for each partition.
Furthermore, Kafka brokers handle the replication of Kafka topic partitions. By replicating data across multiple brokers. Kafka provides fault tolerance and high availability, ensuring that messages are not lost even if a broker goes down.
In summary, a Kafka broker plays a crucial role in a Kafka cluster by managing and storing Kafka topic partitions. It handles the delivery of messages between Kafka producers and consumers. And maintaining metadata and replication for fault-tolerant and scalable storage.
How does Kafka handle data retention and cleanup?
Kafka provides a flexible and configurable way to manage data retention and cleanup in a Kafka cluster. This is achieved through a setting called the “retention period,”. Which determines how long Kafka keeps messages in a topic before they are eligible for deletion.
Kafka’s retention mechanism works on a per-topic basis, and messages that exceed the configured retention period are automatically deleted. Additionally, Kafka supports the option to configure the retention period based on the size of a topic’s log files.
Kafka also offers log compaction, which retains only the latest value for each key in a topic. This is useful for scenarios where you need to retain the latest state for each key but don’t require a history of all messages.
By setting appropriate retention periods and enabling log compaction, Kafka can efficiently manage data retention and cleanup. This helps ensure that the Kafka cluster operates optimally and minimizes the need for manual maintenance.
What is a Kafka stream, and how does it differ from a Kafka table?
Kafka Stream is a processing library that allows you to process real-time data streams in a Kafka cluster. In contrast, Kafka Table is a structured view of data stored in a Kafka topic that can be queried like a database table.
A Kafka Stream is designed for real-time processing of data streams in a Kafka cluster. It allows you to process incoming data streams, transform them, and output the results to other Kafka topics in real-time. Kafka Streams is useful in scenarios where you need to perform real-time analysis or aggregation of data streams. Such as fraud detection or real-time analytics.
On the other hand, a Kafka Table is a structured representation of data stored in a Kafka topic. Kafka Tables are defined by a schema and can be queried using standard SQL-like syntax. Kafka Tables are useful when you need to query the data stored in a Kafka topic. Such as performing ad-hoc analysis or generating reports.
The key difference between Kafka Streams and Kafka Tables is their use case. Kafka Streams is designed for real-time processing of data streams. While Kafka Tables are intended for querying data stored in Kafka topics. While both Kafka Streams and Kafka Tables are part of the Kafka ecosystem. They serve different purposes and are suited for different types of data processing tasks.
In summary, Kafka Streams and Kafka Tables are two key components of the Kafka ecosystem. While Kafka Streams is designed for real-time processing of data streams. Kafka Tables are intended for querying data stored in Kafka topics. By understanding the differences between these two components, you can choose the right tool for your specific data processing needs.
How does Kafka handle message ordering and message delivery guarantees?
Kafka provides robust message ordering and delivery guarantees by using a combination of partitioning, replication, and producer configuration.
Kafka guarantees that messages are delivered to consumers in the order in which they were produced. This is achieved by partitioning data across multiple brokers in a Kafka cluster. Each partition is assigned a unique identifier and stored on one or more brokers. Producers can choose to produce messages to a specific partition, or Kafka can use a partitioner to assign messages to partitions automatically.
In addition to partitioning, Kafka provides replication to ensure high availability and fault tolerance. Each partition is replicated across multiple brokers, with one broker designated as the leader and the others as followers. The leader broker is responsible for handling read and write requests for the partition. While the followers replicate the data to ensure that it is always available in case of a broker failure.
Kafka also provides configurable delivery guarantees to meet the needs of different use cases. Producers can choose from three different levels of message delivery guarantees: “at most once,” “at least once,” and “exactly once.” These delivery guarantees provide different trade-offs between message delivery latency, throughput, and data accuracy.
“At most once” delivery guarantees that messages may be lost but never duplicated, while “at least once” delivery guarantees that messages are delivered at least once but may be duplicated. “Exactly once” delivery guarantees that messages are delivered exactly once, but this level of guarantee comes at the cost of increased processing overhead.
How does Kafka handle data serialization and deserialization?
Kafka supports data serialization and deserialization through a pluggable serialization framework. This framework allows you to use different serialization formats to encode and decode messages in Kafka.
When you produce a message to a Kafka topic, you must first serialize the data into a byte array. Kafka supports several serialization formats, including JSON, Avro, and Protobuf, among others. You can choose the serialization format that best fits your data format and use case.
Similarly, when you consume a message from a Kafka topic, you must deserialize the byte array into its original data format. Kafka’s serialization framework automatically selects the appropriate deserializer based on the message’s serialization format.
By default, Kafka uses the byte array serializer, which simply encodes the data as a sequence of bytes. However, you can configure the serializer and deserializer for each topic to use a different serialization format if desired.
Kafka also provides support for schema evolution, which allows you to evolve the schema of your data over time without breaking compatibility. This is particularly useful when using a schema-based serialization format like Avro or Protobuf.
In summary, Kafka supports data serialization and deserialization through a pluggable serialization framework. This framework allows you to choose the serialization format that best fits your data format and use case. Additionally, Kafka supports schema evolution, allowing you to evolve your data schema over time without breaking compatibility.
How does Kafka handle data compression and decompression?
Kafka supports data compression and decompression using various codecs to reduce the size of stored data and network bandwidth usage during data transmission.
By default, Kafka offers built-in support for Gzip, Snappy, LZ4, and Zstandard compression codecs. You can choose a codec when you produce a message to a Kafka topic, and Kafka compresses the message before storing it. When you consume a message, Kafka detects the compression codec used to compress the message and decompresses it before delivering it to the consumer.
Using compression codecs can significantly reduce the amount of disk space and network bandwidth required to transmit data between producers and consumers. However, there is a trade-off in terms of increased CPU usage, as compression and decompression require additional computational resources. Thus, you should consider the trade-off between compression savings and CPU usage when choosing a compression codec.
In summary, Kafka offers support for different compression codecs to reduce the size of stored data and network bandwidth usage during data transmission. By choosing a compression codec, you can optimize the performance of your Kafka cluster.
What is a Kafka Connect, and how does it integrate with Kafka?
Kafka Connect is a framework for building and running data import and export connectors for Apache Kafka. It is a tool that enables the integration of Kafka with external systems, such as databases, file systems, and messaging systems.
Connectors in Kafka Connect are responsible for moving data between Kafka and external systems. Kafka Connect provides pre-built connectors for popular data sources and sinks such as JDBC, Elasticsearch, HDFS, Amazon S3. You can also develop custom connectors using the Kafka Connect API.
Kafka Connect is designed to be scalable and fault-tolerant. Connectors can run in a distributed mode. Where multiple instances of a connector can be run across multiple nodes for high availability and scalability. Kafka Connect also provides a REST API for managing connectors, which makes it easy to configure, deploy, and monitor connectors.
Using Kafka Connect, you can easily integrate data from external systems into Kafka for processing and analysis. You can also export data from Kafka to external systems, making it easy to share data between different applications.
In summary, Kafka Connect is a framework for building and running data import and export connectors for Kafka. It enables the integration of Kafka with external systems, provides pre-built connectors for popular data sources and sinks. It allows the development of custom connectors using the Kafka Connect API. Kafka Connect is scalable, fault-tolerant, and easy to manage through its REST API.
How does Kafka handle scaling and load balancing in a distributed cluster?
Kafka is built to handle scaling and load balancing in a distributed cluster, ensuring high throughput and performance by adding more nodes as needed.
To achieve this, Kafka partitions topics into multiple partitions, with each partition hosted on a separate broker. This allows for parallel processing of messages across multiple brokers, resulting in fault tolerance in case of broker failures.
When new brokers are added to the cluster or existing brokers go offline, Kafka supports automatic partition rebalancing. The cluster controller detects changes in the broker set and initiates rebalancing by assigning partitions to available brokers based on load and other factors.
To provide fault tolerance and data redundancy, Kafka supports multiple replication factor options. Each partition can be replicated across multiple brokers, ensuring multiple copies of the data are always available even if some brokers go offline.
Additionally, Kafka consumers can be grouped into consumer groups, allowing for load balancing of messages across multiple consumers. Each consumer in a group is assigned a subset of partitions to consume from, and the load is balanced across the consumers in the group. If a consumer goes offline, the remaining consumers in the group automatically rebalance the partitions.
Kafka’s partitioning and replication features, combined with its automatic partition rebalancing and consumer group load balancing capabilities, make it easy to scale and balance the load in a distributed cluster. These features make Kafka an ideal solution for handling large-scale data processing and streaming workloads.
What is a Kafka offset, and how is it used by Kafka consumers?
Kafka offset is a unique identifier assigned to each message that is consumed by a Kafka consumer. It represents the position of the message within the partition and is used to track the progress of the consumer.
Kafka consumers use offsets to keep track of the messages they have already consumed and to determine which messages to consume next. The consumer can choose to start consuming from the earliest offset available in a partition or from a specific offset within a partition.
By keeping track of the offset, Kafka consumers can resume consumption from where they left off in case of a failure or when a new consumer is added to a consumer group. This ensures that messages are not missed, and processing can continue from the point of failure or where the new consumer is added.
Kafka also supports committing offsets, which allows consumers to acknowledge that they have successfully processed a message. This can be done manually or automatically by the consumer. By committing the offset, the consumer group coordinator knows that the messages have been successfully processed, and the offset is updated accordingly.
Kafka offsets are stored in Kafka itself, usually in a dedicated topic named “__consumer_offsets”. This topic is replicated across multiple brokers to ensure fault tolerance and data redundancy.
In summary, Kafka offset is a unique identifier assigned to each message consumed by a Kafka consumer. It’s used to keep track of the progress of the consumer and determine which messages to consume next. By keeping track of the offset, Kafka consumers can resume consumption from where they left off. Kafka supports committing offsets to acknowledge successful processing of messages. Kafka offsets are stored in Kafka itself, ensuring fault tolerance and data redundancy.
What is the role of ZooKeeper in a Kafka cluster?
ZooKeeper plays a crucial role in managing and coordinating a Kafka cluster. It serves as a distributed coordination service that provides a centralized configuration, synchronization, and naming registry for distributed systems like Kafka.
In a Kafka cluster, ZooKeeper is responsible for maintaining the broker configuration, tracking the status of Kafka brokers. keeping track of topics, partitions, and their respective leaders. It also manages the membership of Kafka brokers in the cluster, handling broker failures and leader elections in case of a failure.
ZooKeeper also plays a critical role in managing Kafka consumer groups. It tracks the offset of each consumer group, ensuring that each consumer in the group is processing messages from the correct position.
ZooKeeper achieves this by using a distributed consensus protocol called ZAB (ZooKeeper Atomic Broadcast).Which ensures that all ZooKeeper nodes have a consistent view of the cluster state. This makes ZooKeeper highly available and fault-tolerant, ensuring that the Kafka cluster continues to function even if some ZooKeeper nodes go offline.
In summary, ZooKeeper plays a vital role in managing and coordinating a Kafka cluster by providing a centralized configuration, synchronization, and naming registry. It manages the broker configuration, tracks the status of Kafka brokers, and handles broker failures and leader elections. ZooKeeper also tracks the offset of each consumer group and ensures that the Kafka cluster continues to function even if some ZooKeeper nodes go offline.
What are the best practices for configuring a Kafka cluster for optimal performance?
Configuring a Kafka cluster for optimal performance requires careful consideration of various factors. Such as hardware resources, network settings, Kafka broker and producer configurations, and consumer configurations.
Here are some best practices for configuring a Kafka cluster for optimal performance:
-
Hardware resources: Choose hardware with high disk I/O performance, CPU processing power, and memory capacity to handle large data volumes efficiently.
-
Network settings: Configure the network settings such as socket buffer sizes, TCP keepalives, and maximum transmission unit (MTU) to optimize network throughput and latency.
-
Kafka broker configurations: Tune the Kafka broker configurations such as number of partitions, replication factor, batch size, and message size to optimize message throughput and reduce latency.
-
Producer configurations: Optimize producer configurations such as batch size, linger.ms, and compression type to improve message throughput and reduce network latency.
-
Consumer configurations: Tune consumer configurations such as fetch.min.bytes, max.poll.records, and enable.auto.commit to optimize consumer performance and reduce message processing latency.
-
Monitoring and performance tuning: Monitor Kafka cluster performance using tools such as JMX and Kafka metrics and use this data to optimize Kafka configurations further.
-
High availability and fault tolerance: Configure Kafka to provide high availability and fault tolerance by enabling replication, maintaining multiple replicas, and configuring partition reassignment and leader elections.
In summary, configuring a Kafka cluster for optimal performance involves optimizing hardware resources, network settings. By following these best practices, you can ensure that your Kafka cluster performs at its best, delivering high throughput and low latency messaging.
How can you monitor Kafka for performance and reliability issues?
Monitoring Kafka for performance and reliability issues is critical to ensure the smooth functioning of a Kafka cluster. Here are some ways to monitor Kafka for performance and reliability issues:
-
Kafka metrics: It provides a set of metrics that can be monitored to track the performance and health of the Kafka cluster. These metrics include broker, topic, partition, and consumer group metrics.
-
JMX monitoring: Kafka exposes JMX (Java Management Extensions) metrics. Which can be monitored using tools such as JConsole, JVisualVM, and other monitoring tools that support JMX.
-
Log monitoring: Monitoring Kafka logs can help detect issues. Such as broker failures, slow processing, and other errors that can affect the performance and reliability of the Kafka cluster.
-
Third-party monitoring tools: There are several third-party monitoring tools available that can help monitor Kafka clusters for performance and reliability issues. These tools include Datadog, Prometheus, Grafana, and Nagios, among others.
-
Alerting: Setting up alerts for critical Kafka metrics can help detect issues and prevent potential problems before they become severe.
-
Load testing: Conducting load testing on the Kafka cluster can help identify potential performance issues and bottlenecks.
-
Capacity planning: Monitoring the capacity of the Kafka cluster and planning for future growth can help ensure that the Kafka cluster can handle the increasing data volume and workload.
In summary, monitoring Kafka for performance and reliability issues involves monitoring Kafka metrics, JMX, logs. Using third-party monitoring tools, setting up alerts, conducting load testing, and capacity planning. By monitoring Kafka for performance and reliability issues regularly. You can ensure that your Kafka cluster is performing optimally and avoid potential problems.
What are some common Kafka use cases, and how is Kafka used in real-world scenarios?
Kafka is a super versatile and popular messaging system that is used by many different industries and for a variety of purposes. Let’s explore some of the most common ways Kafka is used in real-world scenarios:
-
Messaging: Kafka is great for real-time data processing, message queuing, and event-driven architectures. It’s used by many messaging platforms to move massive amounts of data between different data systems.
-
Log aggregation: Kafka is awesome for collecting and analyzing logs from various systems and applications, making it easier to troubleshoot issues. Big players like Yelp, Pinterest, and LinkedIn use Kafka for this purpose.
-
Stream processing: Kafka is perfect for stream processing applications like machine learning, data analysis, and fraud detection. Uber uses it to power its stream processing platform, which handles billions of events daily.
-
Data integration: Kafka makes data integration and synchronization between different systems and sources a breeze. Cisco uses Kafka to integrate data from various sources and create real-time dashboards for its IT infrastructure.
-
Microservices: Kafka is a great way to enable communication between different microservices through a central messaging system. The New York Times uses Kafka to allow microservices communication and real-time data processing for its content management system.
-
Internet of Things (IoT): Kafka is a popular choice for IoT use cases because it enables real-time data processing and communication between devices. The BMW Group uses Kafka to process data from its connected vehicles and provide real-time insights to its customers.
In a nutshell, Kafka is a fantastic tool that can be used in a variety of ways to build reliable, distributed, and high-performance data systems. By leveraging Kafka’s scalability and real-time processing capabilities, businesses can make faster and more informed decisions that can give them an edge in their respective industries.
What are some limitations or drawbacks of using Kafka in certain scenarios?
While Kafka is a powerful and versatile tool, it’s essential to keep in mind that there are some limitations and trade-offs to consider when using it in certain scenarios. Here are a few common limitations of using Kafka:
-
High overhead: Due to its distributed architecture and multiple components, Kafka can have a high overhead. Which can require additional resources and increase operational complexity.
-
Complexity: Kafka can be complex to set up and maintain, especially for users who are not familiar with distributed systems or event-driven architectures.
-
Message ordering: While Kafka provides strong message delivery guarantees, maintaining strict message ordering can be challenging, especially when using multiple partitions.
-
Data retention: Kafka is designed for high-velocity data processing, which can lead to large amounts of data retention if not managed properly. This can cause storage and backup challenges.
-
Network latency: Kafka is a distributed system that relies heavily on network communication. Which can lead to higher latency, particularly for geographically distributed clusters.
-
Limited query capabilities: Kafka is primarily designed for message processing and may not be the best tool for use cases that require complex query capabilities or transactional data processing.
It’s essential to understand these limitations and trade-offs to make informed decisions about whether Kafka is the right tool for your use case. However, with careful planning and management, Kafka can be an excellent tool for many different types of data processing and communication.
How does Kafka integrate with other data processing and streaming technologies, such as Spark and Flink?
Kafka is a powerful tool for data processing and streaming, and it can integrate with other popular data processing and streaming technologies such as Apache Spark and Apache Flink.
Apache Spark is a popular big data processing engine that can easily consume data from Kafka using the Spark Streaming API. Spark Streaming allows users to create fault-tolerant streaming applications that process data in real-time from various sources, including Kafka.
Apache Flink is another popular stream processing engine that supports Kafka as a data source and sink. Flink can read from and write to Kafka topics, making it easy to integrate Kafka into Flink streaming applications.
Additionally, Kafka provides connectors to integrate with other popular data processing and streaming technologies, such as Apache Storm, Apache Samza, and Apache NiFi. These connectors enable users to easily move data between Kafka and these other technologies, creating powerful and flexible data processing pipelines.
Integrating Kafka with other data processing and streaming technologies can help organizations build more robust and flexible data processing pipelines. That can handle diverse data sources and use cases. With Kafka’s easy-to-use connectors and APIs, integrating with other technologies is a breeze.
Hope this will help you crack your next Kafka interview. You can also visit our other Blog Post based on other trending Technologies.